Crack Coding Interviews by Building These 5 Real-World Features
Today, we’ll prep for coding interviews a bit differently and build five real-world features for companies like Netflix and Facebook

Preparing for coding interviews is no easy task. You need the skills to break down the problem and to deploy the right tools. The Educative Team has always been on the mission to make coding interview prep more accessible for engineers. We’ve learned firsthand that the best way to succeed is not to memorize 1,500+ LeetCode problems.
That’s why we want to approach interview prep a bit differently today by tackling some real-world problems faced by tech companies. Learning how to build real-world features (e.g. how to merge recommendations on Amazon) is more fun, and it’s much easier to remember what you learned that way. If you can understand a problem’s underlying pattern, you can apply it to just about any question.
We will dive into the solutions for a few common real-world coding problems and build five features. We will offer our solutions in Java.
This tutorial at a glance:
- Netflix feature: Group similar titles (hashmaps)
- Facebook feature: Friend circles (DFS)
- Google Calendar feature: Find meeting rooms (Heaps)
- Amazon feature: Products in price range (BST)
- Twitter feature: Add likes (Strings)
- Where to go from here
1. Netflix Feature: Group Similar Titles (hash maps)
Netflix is one of the biggest video streaming platforms out there. The Netflix engineering team is always looking for new ways to display content. For this first problem, imagine you’re a developer on this team.
Task: Our task here is to improve search results by enabling users to see relevant search results without being hindered by typos. We are calling this the “Group Similar Titles” feature.
First, we need to determine how to individually group any character combination for a given title. Let’s imagine that our library has the following titles: "duel," "dule," "speed," "speed," "deul," and "cars." You are tasked to design a functionality so that if a user misspells a word (e.g. “speed” as “spede”), they will still be shown the correct title.
First, we need to split our titles into sets of words so that the words in a set are anagrams. We have three sets: {"duel", "dule", "deul"},{"speed", "spede"}, and {"cars"}. The search results should include all members of the set that the string is found in. It’s best to pre-compute our sets rather than forming them when a user searches.
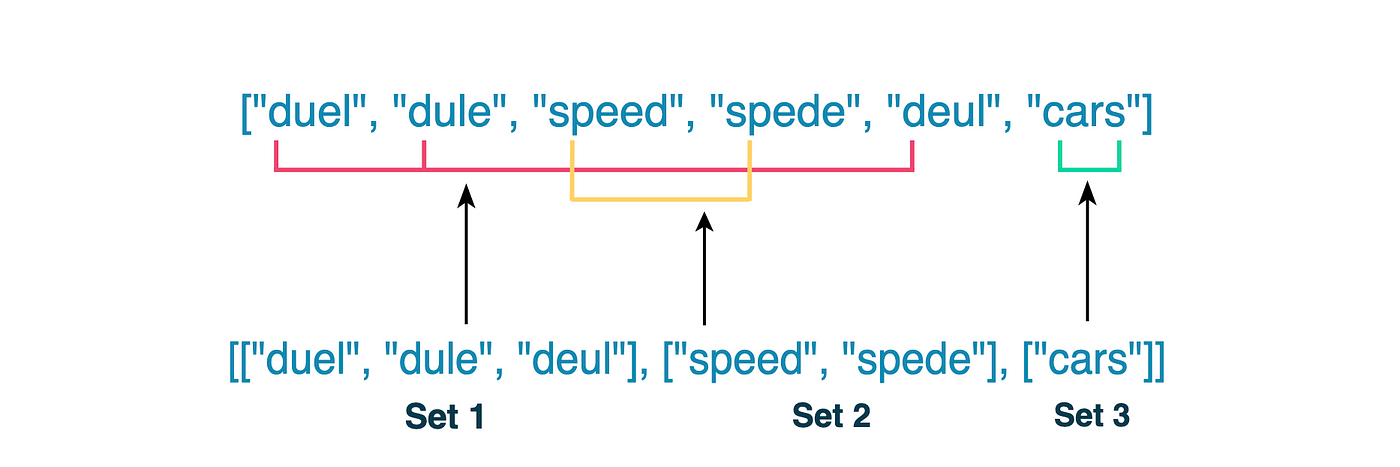
The members of each set have the same frequency of each alphabet, so the frequency of each alphabet in words in the same group is equal. For example, in our {{"speed", "spede"}} set, the frequency of the characters is the same in each word: s, p, e, and d.
So, how do we design and implement this functionality? Let’s break it down.
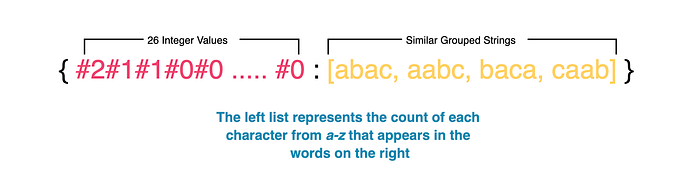
- For each title, we need to compute a 26-element vector. Each vector element represents the frequency of an English letter in a title. We can represent frequency using a string that is fixed with
#characters. This mapping process generates identical vectors for the strings that are anagrams. For example, we representabbcccas#1#2#3#0#0#0...#0. - We then use this vector as a key for inserting titles into a hashmap. Our anagrams will all be mapped to the same entry. When a user searches a title or word, it should compute the 26-element English letter frequency vector based on input. It will then search the hashmap and return all the map entries using the vector.
- We then store a list of calculated character counts as a key in a hashmap and assign a string as its value.
- Each value is an individual set, so we return the values of the hashmap.
Java solution
If you want to see the solution in Python, check out the original post.
Complexity measures
- Time complexity: O(n∗k) since we are counting each letter for each string in a list.
- Space complexity: O(n∗k) since every string is stored as a value in the dictionary and the size of the string can be k.
2. Facebook Feature: Friend Circles (DFS)
Facebook is the biggest social media company in the world. They also own and operate Instagram. Pretend you are a Facebook engineer team and you are tasked to improve integration among their sister platforms.
Task: Our task here is to find all the people on Facebook who are in a user’s friend circle. We are calling this the “Friend Circles” feature.
We need to first identify the people who are in each user’s friends circle, which includes users who are directly or indirectly friends with another user. Let’s assume there are n users on Facebook. The friendship connection is transitive.
Example: If Nick is a direct friend of Amy, and Amy is a direct friend of Matt, then Nick is an indirect friend of Matt.
We will use an n*n square matrix. For example, cell [i,j] will hold value 1 if these users are friends. If not, the cell will hold the value 0. In the illustration below, there are two friend circles from the example above. Nick is only friends with Amy, but Amy is friends with Nick and Matt. This forms a friend circle. Mario makes another friend circle on his own.
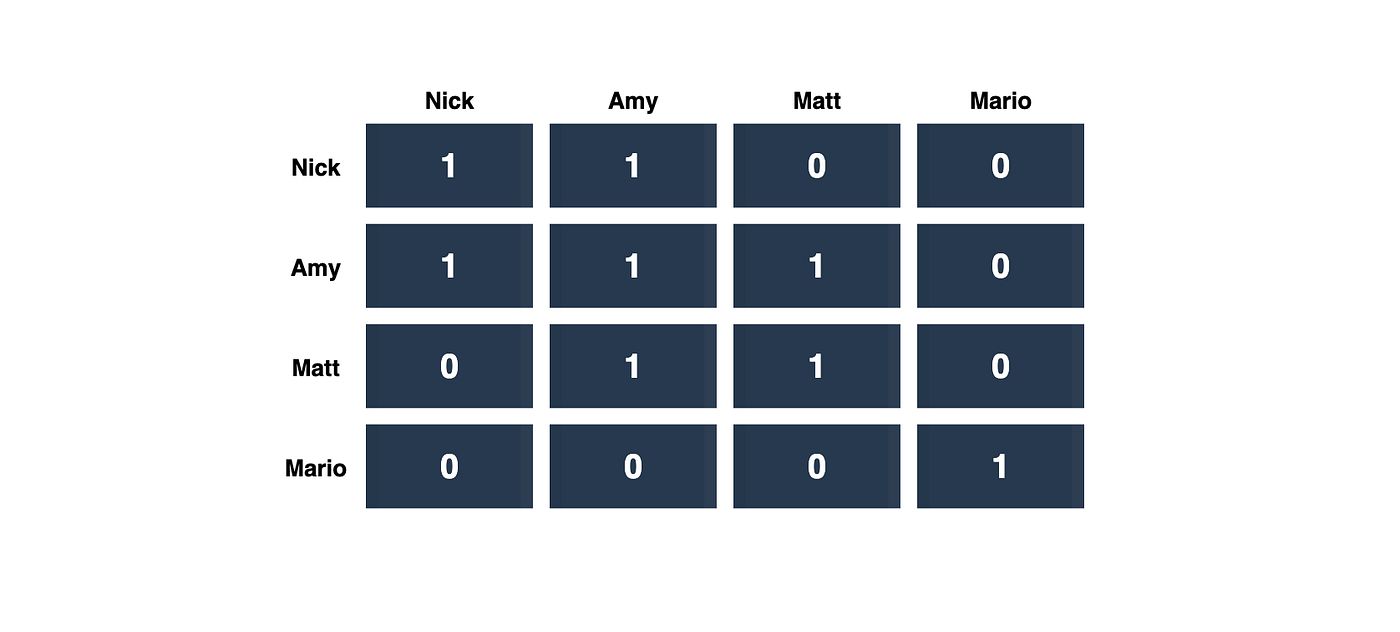
Think of our symmetric input matrix as an undirected graph. Both the indirect and direct friends who are in one friend circle also exist in one connected component in our graph. This means that the number of connected graph components will give us how many friend circles we have.
So, our task is to find the number of connected components. We treat the input matrix as an adjacency matrix. So, how do we design and implement this? Let’s break it down.
- First, we initialize an array named
visited. This will track the visited vertices of sizenwith0as the value for each index. - Then, we traverse the graph using DFS if
visited[v]is0. If not, we move to the nextv. - Then, set
visited[v]to1for everyvthat our DFS traversal runs into. - When the DFS traversal is done, we should increment the circle counter by
1. This means that a connected component has been fully traversed.
Java solution
Complexity measures
- Time complexity: O(n2) because we traverse the complete matrix of size n².
- Space complexity: O(n) because the
visitedarray that stores our visited users is of size n.
3. Google Calendar Feature: Find Meeting Rooms (Heaps)
The Google Calendar tool is part of the GSuite used to manage events and reminders. Imagine you are a developer on the Google Calendar application team, and you’re tasked with implementing some productivity-enhancing features.
Task: Your goal is to create a functionality for scheduling meetings. You need to determine and block the minimum number of meeting rooms for these meetings.
To do this, we are given some meeting times. We need to find a way to identify the number of meeting rooms needed to schedule them all. Each meeting will contain positive integers for a startTime and an endTime.
Our meeting times can be listed as follows: {{2, 8}, {3, 4}, {3, 9}, {5, 11}, {8, 20}, {11, 15}}. We could schedule each meeting in a separate room, but we want to use the minimum amount of rooms. We observe that three meetings overlap: {2, 8}, {3, 4}, and {3, 9}. Therefore, at least these three will require separate rooms.
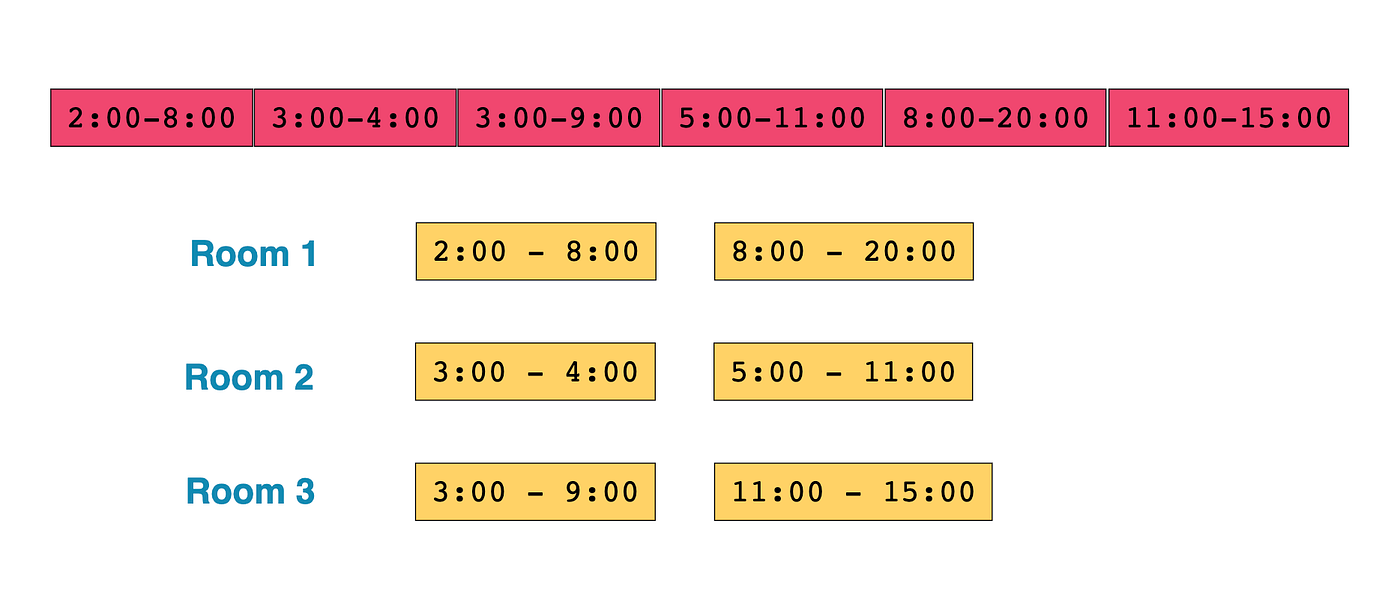
To solve this, we use either a heap or priority queue for storing meeting times, using the end_time of each meeting as a key. The room at the top of our heap would become free earliest. If the meeting room from the top of the heap is not free, then no other room is free yet.
So, how do we build this functionality? Let’s break it down.
- Sort the meetings by
startTime. - Allocate the first meeting to a room. Add the
endTimeas an entry in the heap. - Traverse the other meetings and check if the meeting at the top has ended.
- If the room is free, extract this element and add it to the heap again with the end time of the current meeting we want to process. If it is not free, allocate a new room and add it to our heap.
- After processing the list of meetings, the size of the heap will tell us how many rooms are allocated. This should be the minimum number of rooms we need.
Java solution
If you want to see the solution in Python, check out the original post.
Complexity measures
- Time complexity: O(n∗log(n))
- Space complexity: O(n), where n is the number of meetings.
4. Amazon Feature: Products in Price Range (BST)
Amazon is the largest online store around the world, and they are always on the lookout for better ways to recommend products to their customers. Imagine you are a developer for Amazon’s store.
Task: Implement a search filter to find products in a given price range. The product data is in the form of a binary search tree. The values are the prices of products.
The parameters we are working with are low and high, which represent a user’s price range. The example list of products below are mapped to their prices.
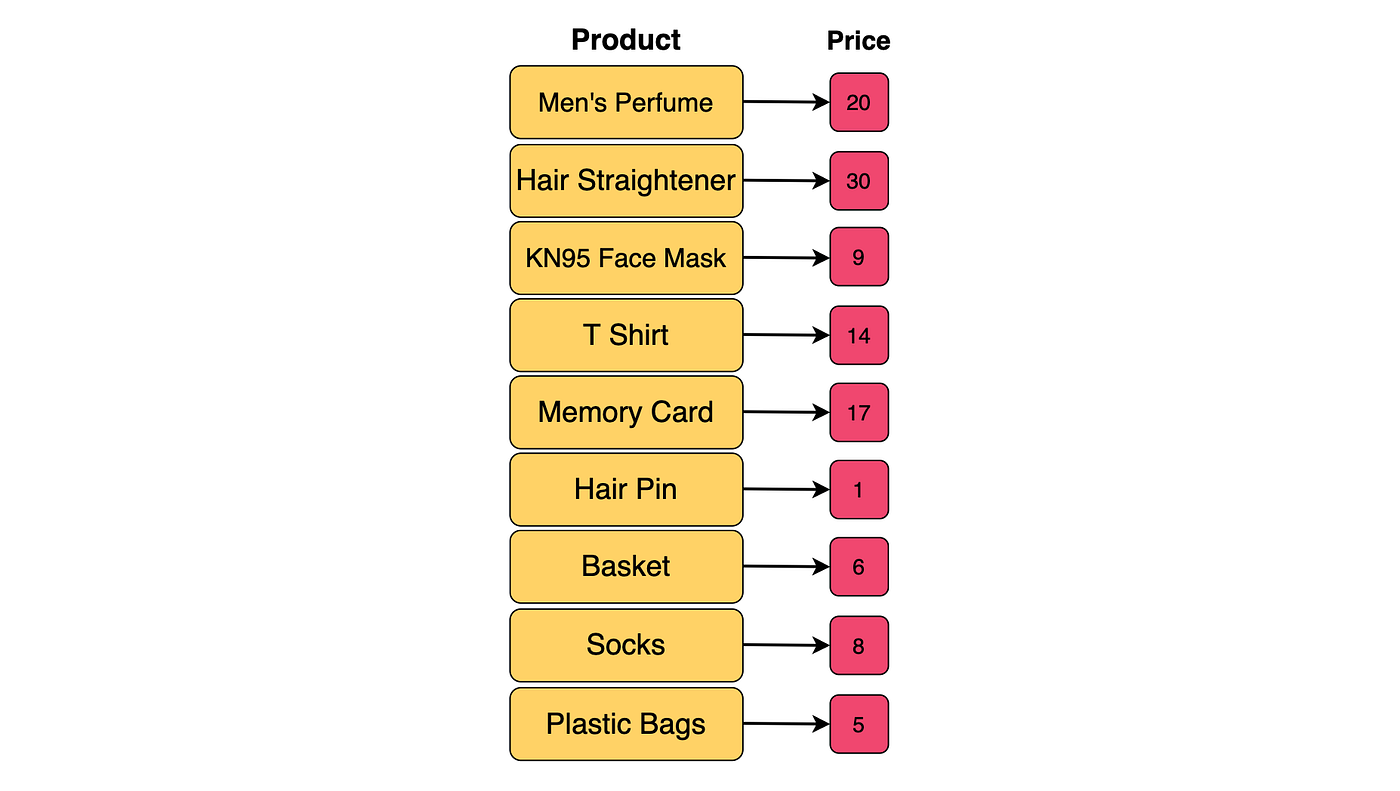
They are then stored in a binary search tree:
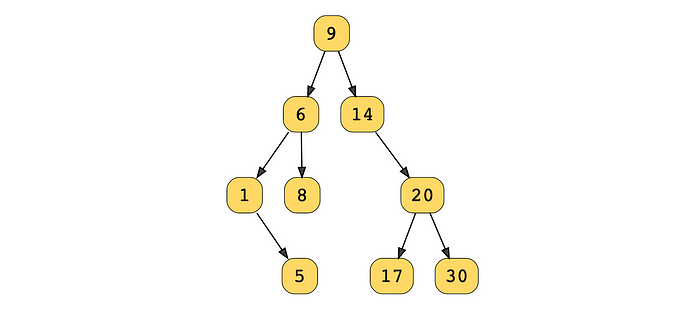
We can assume that the selected price range is low = 7 and high = 20, so our function solution should only return the prices {9, 8, 14, 20, 17}. So, how do we implement this? Let’s break it down.
We will solve this problem using a variation of a preorder traversal on a binary tree, but other binary tree traversals would work as well.
- Implement a recursive helper function for a preorder traversal.
- Check if the current node value is in our given range. If so, add it to the
outputarray. - Recursively call the preorder function on the left child of the node if the current node value is greater than or equal to
low. - If the current node value is less than or equal to
high, recursively traverse the right child of the node. - When traversal is completed, the
outputarray will be returned.
Java solution
BinarySearchTree.java:https://betterprogramming.pub/media/287e7de330a781d790342a126f8b5bbc
main.java:https://betterprogramming.pub/media/0cba0f55a23a5275384e3acc517e010c
If you want to see the solution in Python, check out the original post.
Complexity measures
- Time complexity: O(n)
- Space complexity: O(n)
5. Twitter Feature: Add Likes (Strings)
Twitter is a popular social media platform. Imagine you’re a Twitter developer, and your team must create an API that calculates the number of likes on a given person’s tweets.
Task: Create an API that calculates the total number of likes on a person’s tweets. Create a module that takes two numbers and returns the sum of the numbers.
The data is already extracted and stored in a simple text file for you. All of the values should remain strings and cannot be converted into integers. We must do digit-by-digit addition due to these restrictions. So, how do we create this module? Let’s break it down.
- Initialize an empty
resvariable and thecarryas0. - Then, set two pointers (
p1andp2) that will point to the end oflike1andlike2. - Traverse the strings from the end using these pointers. Set it to stop when both strings are done.
- Set
x1equal to a digit from stringlike1atindex p1. Ifp1has reached the beginning oflike1, setx1to0. Do the same forx2withlike2atindex p2. - Compute the current value using
value = (x1 + x2 + carry) % 10. Then update thecarryso thatcarry = (x1 + x2 + carry) / 10. - Append the current value to the result.
- If both of the strings are traversed, but the
carryis still non-zero, append thecarrytores. - Lastly, reverse the result and convert it to a string. Return the final string.
Java solution
Complexity measures
- Time complexity: O(max(n¹,n²))
- Space complexity: O(max(n¹,n²))
Where To Go From Here
Congrats on making it to the end! You just built five real-world features using skills like DFS, BST, heaps, and more. As you can see, this is a powerful way to prepare for coding interviews that tends to be more effective. If you can understand a problem’s underlying pattern, you can solve just about any question. This is coding interview prep reimagined. Happy learning!
There are still dozens of other practice problems like these out there, like:
- Merge tweets in a Twitter feed
- AT&T determine location
- Zoom: Display lobby meeting
- Search engine: Fetch words
- And more